다항 논리회귀를 공부하며 캐글(Kaggle)의 dataset을 활용해 실습한 내용을 기록하기 위해 작성한 글이다
순서
Kaggle에서 wine 정보(wineuci)를 다운로드 받아 와인의 정보를 이용해서 와인을 예측하는 과정은 다음과 같다
1. 캐글(Kaggle) 환경 변수 설정 (os)
2. 데이터셋 다운로드
3. 데이터셋 로드 (pandas.read_csv)
4. 전처리
5. 학습/검증 데이터 분할
6. 모델 학습
1. 캐글(Kaggle) 환경 변수 설정 (os)
import os
os.environ['KAGGLE_USERNAME'] = 'username'
os.environ['KAGGLE_KEY'] = 'key'
2. 데이터셋 다운로드
!kaggle datasets download -d brynja/wineuci
!unzip wineuci.zip
3. 데이터셋 로드 (pandas.read_csv)
df = pd.read_csv('Wine.csv')
df.head(5)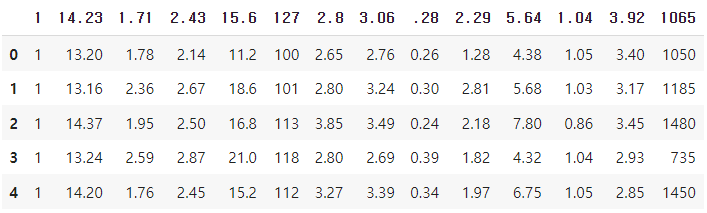
header의 내용이 14.23, 1.71, ... 으로 불친절한 것을 알 수 있다
header의 내용을 채워주자
df = pd.read_csv('Wine.csv', names=[
# name이 와인의 종류가 될 것
'name',
'alcohol',
'malicAcid',
'ash',
'ashalcalinity',
'magnesium',
'totalPhenols',
'flavanoids',
'nonFlavanoidPhenols',
'proanthocyanins',
'colorIntensity',
'hue',
'od280_od315',
'proline'
])
df.head(5)
# 입력값은 name을 제외한 모든 칼럼, 출력값은 name이 된다. (1, 2, 3)이라는 3가지 종류의 와인
4. 전처리
[비어있는 값을 포함한 행 제거]
print(df.isnull().sum())
# 비어있는 행 없음
[X, Y 데이터 분할]
x_data = df.drop(columns=['name'], axis=1) # name 칼럼을 제외한 모든 데이터를 x_data에 포함
x_data = x_data.astype(np.float32)
x_data.head(5)
y_data = df[['name']] # name 칼럼만 y_data에 포함
y_data = y_data.astype(np.float32)
y_data.head(5)
[표준화]
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
print(x_data.values[0]) # 데이터 표준화 전
print(x_data_scaled[0]) # 데이터 표준화 후
★ [One-hot encoding] ★
# y_data로 One-hot encoding
# 기존 y_data는 1, 2, 3 세 종류가 있었다
# One-hot encoding은 아래와 같이 바꿔준다
# 1 [0 , 0 , 0] -> [1 , 0 , 0]
# 2 [0 , 0 , 0] -> [0 , 1 , 0]
# 3 [0 , 0 , 0] -> [0 , 0 , 1]
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0]) # OneHotEncoder 적용 전
print(y_data_encoded[0]) # OneHotEncoder 적용 후
5. 학습/검증 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size = 0.2, random_state = 2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
# 36,13의 13은 x_data의 컬럼 개수
# 36,3의 3은 와인의 종류 개수
6. 모델 학습
model = Sequential([
Dense(3, activation='softmax') # 이진 논리 회귀와 다르게 출력이 3개기 때문에 Dense값은 3이고, sigmoid가 아니고 softmax
])
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.02), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data = (x_val, y_val),
epochs=20
)
# val_acc = 0.9166 : 임의의 x 데이터를 넣었을때 91.6% 로 와인의 종류 (1, 2, 3)를 구별할 수 있다
'AI > Machine Leaning' 카테고리의 다른 글
| [Deep Leaning] 알파벳 수화(Sign Language MNIST) 예제 (2) | 2022.05.17 |
|---|---|
| [Deep Learning] 딥러닝의 주요 개념 (Batch, Epoch, Activation, Over/Under fitting) (0) | 2022.05.17 |
| [Machine Learning] 이진 논리회귀(binary logistic regression) 예제 (0) | 2022.05.16 |
| [Machine Leaning] Keras Dence & 활성화(activation) 함수 종류 (0) | 2022.05.16 |
| [Machine Learning] 선형회귀(linear regression) 예제 (0) | 2022.05.12 |